3. Causality vs Correlation#
Intuitively, we all understand cause and effect relationships; rain causes a wet pavement but a wet pavement does not cause rain. Getting a computer to understand these relationships is tricky. Current state of the art machine learning algorithms are very good at exploiting data correlations and applied to lots of problems very successfully however it does have limitations which we will introduce in this section.
This article is an introduction to causal inference. I am not an expert in this topic so this contains some of my own thoughts and questions.
3.1. Spurious correlations#
There is a wealth of humorous correlation examples out in the literature. Tyler Vigen hosts a website (https://www.tylervigen.com/spurious-correlations) dedicated to finding highly correlated, completely unrelated data. One such dataset is shown below. Unless people named Alix are much more likely steal cars, there is no relation between that and carjackings. Machine learning algorithms that are trained to exploit spurious correlations have real world consequences.
3.2. The IID Assumption#
Modern machine learning relies heavily on the assumption that the training and test data is independently and identically distributed. The assumption has two parts:
- Independently Distributed
Each data point does not influence the other data points. For example, the result of one coin flip does not affect the next.
- Identically Distributed
Every data point comes from the same probability distribution.
These assumptions are why we split our datasets into a training and test dataset. We assume the test data is sampled from the same distribution as the training data so if a model performs well on the training data, it should also perform well on the test data. We may in-fact train a good model that performs well on the unseen test data but when the model is put into production we find that new data coming does not look like the train/test data, and model performance degrades.
In the Imagenet challenge, huskies tend to be in snowy backgrounds. Some of the best performing models seem to base their dog breed predictions at least in part of the background meaning if the models are presented with a husky in a desert, there is a good chance it will be misclassified.
3.3. How can Causal Inference Help?#
3.4. Randomized Controlled Trials#
Randomized control trials are the gold standard for causal inference. A well designed study lets causal conclusions be drawn from association by [Raw23]:
Making a change to one group but not the other.
Making the treated and control groups comparable by eliminating all sources of bias through randomisation.
Eliminating all sources of cofounders from the treated and controls means that any differences observed between the groups must be due the intervention.
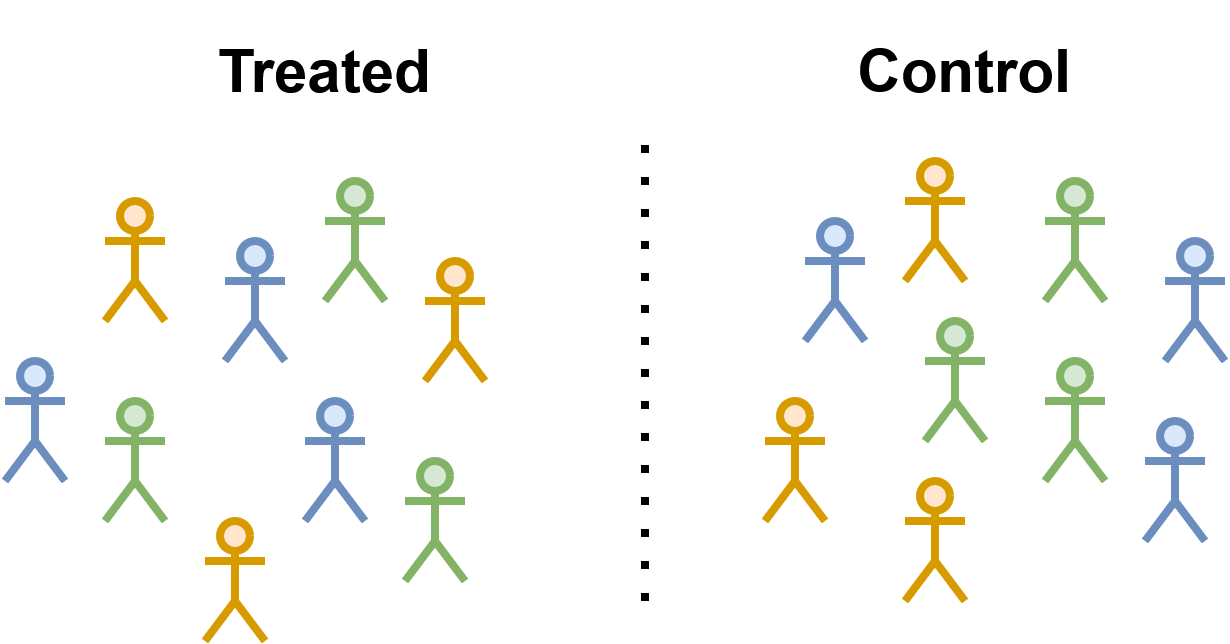
Fig. 3.1 This figures shows the treated and control group in a randomised control. The same number of blue, orange, and green stick figures are in each group so the same cofounders are in both groups.#
Randomised controlled trials can be very expensive and sometimes unethical. For example, suppose we wanted to measure the causal impact of smoking on cancer. Obviously, it would be immoral to ask a group of random participants to smoke for the next 25 years to measure the effect on their health. These kinds of economic and ethical concerns are common, so there is a lot of interest in how we can measure causal effects from purely observational data.
3.5. What are the Problems where you Should Consider Using Causal Inference?#
You should consider using causal inference if you are trying to answer what-if questions.
If I decrease the price of my product, what will be the effect on sales.
There efforts to broaden the scope of causal inference and apply it to more general prediction problems. One are where causal inference is being used is for out of distribution prediction.
3.6. Causal Graphs#
Causal graphs are a compact way to represent the assumptions we make about our data. A causal graph must be directed and acyclic.
Nodes are made up of nodes and edges:
Nodes represent variables or features in the world.
Edges represent a causal relationships that connects two nodes no matter how strong the connection.
Saying two nodes have no edge connecting is a stronger assumption than saying they are connected but their connection is very weak [EK19]. Below is a graph for rain and wet ground, the rain causes the ground to become wet which causes people to slip.

Causal Graphs help us reason about our system to ask questions like: if we intervene to make the ground drier, what is the impact on slips?
3.7. Assumptions#
Suppose we have the graph A -> B -> C. If we change A, that will affect the relationship between A and B but not C [EK19].
3.8. Structural Equations#
A causal graph does not say anything about the relationship between nodes, only that the relationship exists or does not exist. One way to measure the relationship between nodes is with structural equation models. Consider the following DAG:
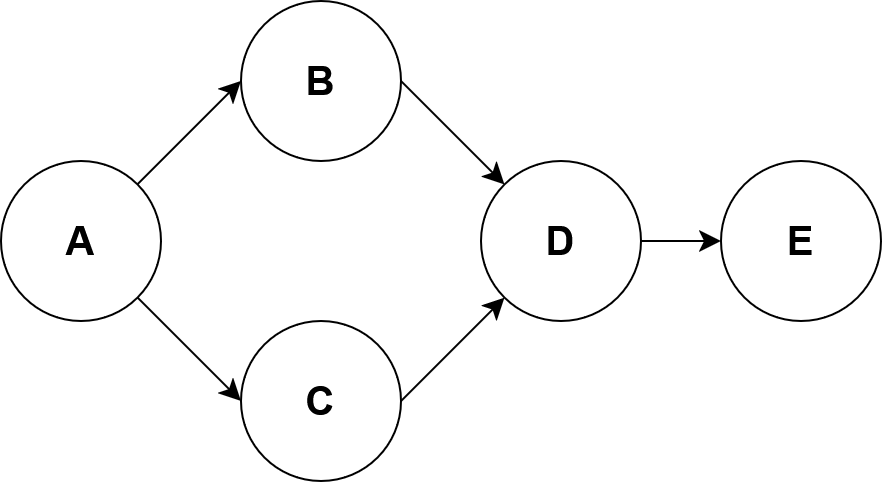
The structural equations for this DAG look like this:
The functions \(f_i\) can take on any form but we can limit things further by enforcing a linear relationships on the functions.
3.9. Structural Equations and Linear Regression#
The equations presented in the previous look very similar to linear regression. So what is the advantage to creating a graphical causal model? We will demonstrate the utility through an example.
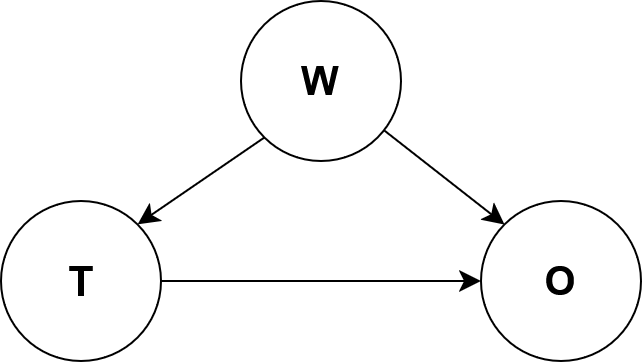
Suppose we want to measure the effectiveness of a drug from the following DAG
where T is the quantity of the drug that is administered, O is
the outcome of some biomarker that we want to improve like blood pressure.
Do a Simpson’s paradox example.
3.10. Pearl’s Ladder of Causation#
Certain types of structural causal models fall on rung three of Pearl’s ladder of causation.
Level |
Activity |
Questions |
Examples |
|---|---|---|---|
1 |
Imagining |
What if I had done X instead of Y. |
Would this image still be classified as a zerbra if it had spikes instead of spots? |
2 |
Intervening |
What if I do X? |
If we ban cigarettes, will smoking reduce? |
3 |
Observing, Association |
What is important? |
What is the breed of dog in this image? |
Traditional machine learning like image classification, regression, and clustering fall on the first third run of Peal’s causation ladder. Structural causal models can be used for intervening and imaging type reasoning.
3.11. Level 2: Intervention through the Outcome Framework#
Interventions questions are things like:
What would the effect be on B if I change the value (intervene) on A.
Consider the following causal graph.
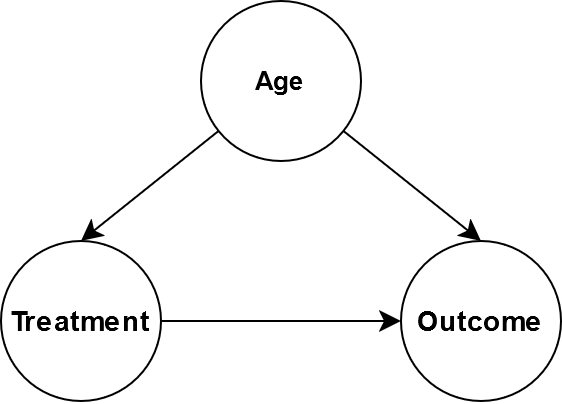
Age affects the treatment and the outcome. Perhaps the treatment dosage has the be reduced depending on age. Suppose that we wanted to give everybody the same treatment regardless of age. One might thing our goal is to determine \(P(O|T=t,A)\) but that is not quite correct. Our intervention means that age no longer causes the treatment so the causal graph becomes:
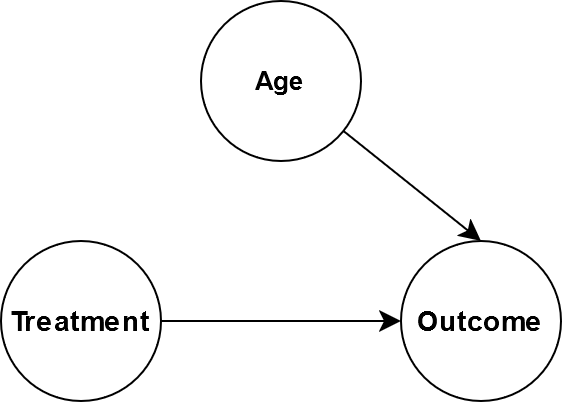
Mathematically, this is written as \(P(O|\text{do}(T))\) where the operator \(\text{do}(T)\) represents the intervention. From this leads nicely onto the idea of an average treatment effect which is the average effect on the population from making an intervention.
Suppose the treatment \(T\) is binary meaning we either apply it (\(1\)), or we do not (\(0\)). In \(\text{do}\) notation, the definition of average an treatment effect is:
Cian Eastwood, Alexander Robey, Shashank Singh, Julius Von Kügelgen, Hamed Hassani, George J Pappas, and Bernhard Schölkopf. Probable domain generalization via quantile risk minimization. Advances in Neural Information Processing Systems, 35:17340–17358, 2022.
Amit Sharm Emre Kiciman. Causal Reasoning: Fundamentals and Machine Learning Applications. 2019.
Judea Pearl. Causality: Models, Reasoning and Inference. Cambridge University Press, USA, 2nd edition, 2009. ISBN 052189560X.
David Rawlinson. An introduction to causal inference with python – making accurate estimates of cause and effect from. https://www.youtube.com/watch?v=ilpSZiDjdv0, May 2023.